Republished with permission from the original author.
Though over 7 years old today, it explains in a succinct and friendly way a fundamental problem that still plagues Machine Learning today.
In a more general sense, it illustrates the rule that understanding the driving mechanisms of phenomena can dissolve both hype and panic, putting a real damper on disarming storytales of “Artificial General Intelligence” and robot takeovers.
— R. D.
If you have been around all the machine learning and artificial intelligence stuff, you surely have already seen this:

Or, if you haven’t, there are some deep convolutional network result samples from ILSVRC2010, by Hinton and Krizhevsky.
Let’s look for a moment at the top-right picture. There’s a leopard, recognized with substantial confidence, and then two much less probable choices are jaguar and cheetah.
This is, if you think about it for a bit, kinda cool. Do you know how to tell apart those three big and spotty kitties? Because I totally don’t. There must be differences, of course — maybe something subtle and specific, that only a skilled zoologist can perceive, like general body shape or jaw size, or tail length. Or maybe is it context/background, because leopards inhabit forests and are more likely to be found laying on a tree, when cheetahs live in savanna? Either way, for a machine learning algorithm, this looks very impressive to me. After all, we’re still facing lots of really annoying and foolish errors like this one. [1] So, is that the famous deep learning approach? Are we going to meet human-like machine intelligence soon?
Well… turns out, maybe not so fast.
Just a little zoological fact
Let’s take a closer look at these three kinds of big cats again. Here’s the jaguar, for example:

It’s the biggest cat on both Americas, which also has a curious habit of killing its prey by puncturing their skull and brain (that’s not really the little fact we’re looking for). It’s the most massive cat in comparison with leopard and cheetah, and its other distinguishing features are dark eyes and larger jaw. Well, that actually looks pretty fine-grained.

Then, the leopard. It’s a bit smaller than the jaguar and generally more elegant, considering, for example, its smaller paws and jaw. And also yellow eyes. Cute.

Then the smallest of the pack, the cheetah. It actually looks quite different from the previous two — has a generally smaller, long and slim body, and a distinctive face pattern that looks like two black tear trails running from the corners of its eyes.
And now, for the part I’ve purposely left out: black spotty print pattern. It’s not completely random, as you might think it is — rather, black spots are combined into small groups called “rosettes.” You can see that jaguar rosettes are large, distinctive and contain a small black spot inside, while leopard rosettes are significantly smaller. As for the cheetah, its print doesn’t contain any, just a scatter of pure black spots.

See how those three prints actually differ.
(Also, thanks Imgur for educating me and providing the pictures.) [2]
Suspicion grows
Now, I have a little bit of bad feeling about it. What if this is the only thing our algorithm does — just treating these three pictures like shapeless pieces of texture, knowing nothing about leopard’s jaw or paws, its body structure at all? Let’s test this hypothesis by running a pre-trained convolutional network on a very simple test image. We’re not trying to apply any visual noise, artificial occlusion or any other tricks to mess with image recognition — that’s just a simple image, which I’m sure everyone who reads this page will recognize instantly.
Here it is:

We’re going to use Caffe and its pre-trained CaffeNet model, which is actually different from Hinton and Krizhevsky’s AlexNet, but the principle is the same, so it will do just fine.
Aaand here we go:
Here’s the result:
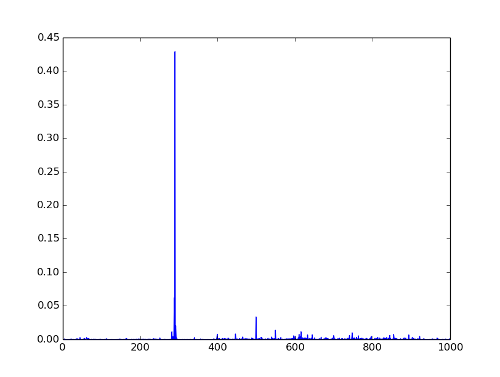
>> predicted class: 290

Whoops.
But wait, maybe that’s just CaffeNet thing? Let’s check something third-party:
Clarifai (those guys did great on the latest ImageNet challenge):

Brand new Stephen Wolfram’s ImageIdentify:
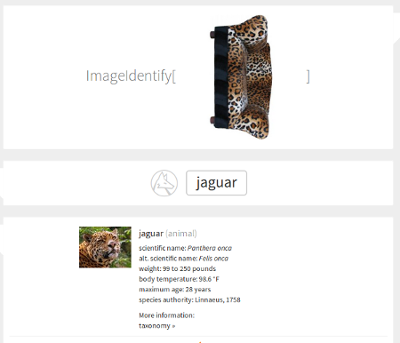
Okay, I cheated a bit: on the last picture the sofa is rotated by 90 degrees, but that’s really simple transformation that should not change the recognition output so radically. I’ve also tried Microsoft and Google services, and nothing has beaten rotated leopard print sofa. Interesting result, considering all the “[Somebody]’s Deep Learning Project Outperforms Humans In Image Recognition” headlines that have been around for a while now.
Why is this happening?
Now, here’s a guess. Imagine a simple supervised classifier, without going into model specifics, that accepts a bunch of labeled images and tries to extract some inner structure (a set of features) from that dataset to use for recognition. During the learning process, a classifier adjusts its parameters using prediction/recognition error, and this is where dataset size and structure matter. For example, if a dataset contains 99 leopards and only one sofa, the simplest rule that tells a classifier to always output “leopard” will result in 1% recognition error while staying not intelligent at all.
And that seems to be exactly the case, both for our own visual experience and for the ImageNet dataset. Leopard sofas are rare things. There simply aren’t enough of them to make difference for a classifier; and black spot texture makes a very distinctive pattern that is otherwise specific to a leopard category. Moreover, being faced with different classes of big spotted cats, a classifier can benefit from using these texture patterns, since they provide simple distinguishing features (compared with the others like the size of the jaw). So, our algorithm works just like it’s supposed to. Different spots make different features, there’s little confusion with other categories and sofa example is just an anomaly. Adding enough sofas to the dataset will surely help (and then the size of the jaw will matter more, I guess), so there’s no problem at all, it’s just how learning works.
Or is it?
What we humans do
Remember your first school year, when you learned digits in your math class.
When each student was given a heavy book of MNIST database, hundreds of pages filled with endless hand-written digit series, 60000 total, written in different styles, bold or italic, distinctly or sketchy. The best students were also given an appendix, Permutation MNIST, that contained the same digits, but transformed in lots of different ways: rotated, scaled up and down, mirrored and skewed. And you had to scan through all of them to pass a math test, where you had to recognize just a small subset of length 10000. And just when you thought the nightmare was over, a language class began, featuring not ten recognition categories, but twenty-five instead.
So, are you going to say that was not the case?
It’s an interesting thing: looks like we don’t really need a huge dataset to learn something new. We perceive digits as abstract concepts, Plato’s ideal forms, or actually rather a spatial combinations of ones, like “a straight line,” “a circle,” “an angle.” If an image contains two small circles placed one above the other, we recognize an eight; but when none of the digit-specific elements are present, we consider the image to be not a digit at all. This is something a supervised classifier never does — instead, it tries to put the image into the closest category, even if likeness is negligible.
Maybe MNIST digits is not a good example — after all, we all have seen a lot of them in school, maybe enough for a huge dataset. Let’s get back to our leopard print sofa. Have you seen a lot of leopards in your life? Maybe, but I’m almost sure that you’ve seen “faces” or “computers” or “hands” a lot more often. Have you actually seen such a sofa before — even once? Can’t be one hundred percent confident for myself, but I think I have not. And nevertheless, despite this total lack of visual experience, I don’t consider the image above a spotty cat in a slightest bit.
Convolutional networks make it worse
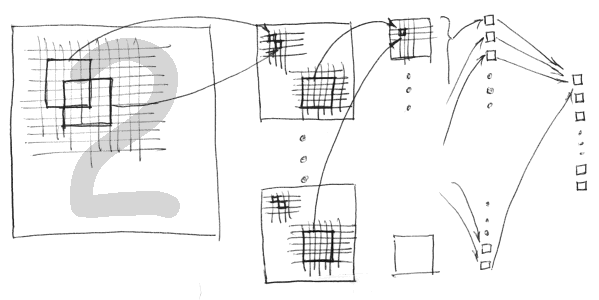
Deep convolutional network are long-time ImageNet champions.
No wonder; they are designed to process images, after all.
If you are not familiar with the concept of CNNs, here’s a quick reminder: they are locally-connected networks that use a set of small filters as local feature detectors, convolving them across the entire image, which makes these features translation-invariant (which is often a desired property).
This is also a lot cheaper than trying to put an entire image (represented by 1024 x 768 = ~800000 naive pixel features) into a fully-connected network.
There are other operations involved in CNNs feed-forward propagation step, such as subsampling or pooling, but let’s focus on convolution step for now.
Leopards (or jaguars) are complex 3-dimensional shapes with quite a lot of degrees of freedom (considering all the body parts that can move independently). These shapes can produce a lot of different 2d contours projected on the camera sensor: sometimes you can see a distinct silhouette featuring a face and full set of paws, and sometimes it’s just a back and a curled tail. Such complex objects can be handled by a CNN very efficiently by using a simple rule: “take all these little spotty-pattern features and collect as many matches as possible from the entire image.” CNNs’ local filters ignore the problem of having different 2D shapes by not trying to analyze leopard’s spatial structure at all — they just look for black spots, and, thanks to nature, there are a lot of them at any leopard picture. The good thing here is that we don’t have to care about object’s pose and orientation, and the bad thing is that, well, we are now vulnerable to some specific kinds of sofas.
And this is really not good. CNNs’ usage of local features allows to achieve transformation invariance — but this comes with the price of not knowing neither object structure nor its orientation. CNNs cannot distinguish between a cat sitting on the floor and a cat sitting on the ceiling upside down, which might be good for Google image search but for any other application involving interactions with actual cats it’s kinda not.
If that doesn’t look convincing, take a look at Hinton’s paper [3] from 2011 where he says that convolutional networks are doomed precisely because of the same reason. The rest of the paper is about an alternative approach, his capsule theory [4] which is definitely worth reading too.
We’re doing it wrong
Maybe not all wrong, and of course, convolutional networks are extremely useful things, but think about it: sometimes it almost looks like we’re already there. We’re using huge datasets like ImageNet and organize competitions and challenges where we, for example, have decreased MNIST recognition error rate from 0.87 to 0.23 (in three years [5]) — but no one really knows what error rate a human brain can achieve. There’s a lot of talk about GPU implementations, like it’s just a matter of computational power now, like the theory is all fine. It’s not. And the problem won’t be solved by collecting even larger datasets and using more GPUs, because leopard print sofas are inevitable. There always going to be an anomaly; lots of them, actually, considering all the things painted in different patterns. Something has to change. Good recognition algorithms have to understand the structure of the image and to be able to find its elements like paws or face or tail, despite the issues of projection and occlusion.
So I guess, there’s still a lot of work to be done.
[1] A snapshot of a phone camera identifying an overweight man’s belly as his face. [web]
[2] “Cheetah vs Leopard vs Jaguar” at Imgur. [web]
[3] G. E. Hinton, A. Krizhevsky & S. D. Wang, 2011. Transforming Auto-encoder. [web]
[4] Ran Bi, 2014. “Geoffrey Hinton talks about Deep Learning, Google and Everything.” KD Nuggets. [web]